Image-based prediction models for disease detection are sensitive to changes in data acquisition such as the replacement of scanner hardware or updates to the image processing software. The resulting differences in image characteristics may lead to drifts in clinically relevant performance metrics which could cause harm in clinical decision making, even for models that generalise in terms of area under the receiver-operating characteristic curve. We propose Unsupervised Prediction Alignment, a generic automatic recalibration method that requires no ground truth annotations and only limited amounts of unlabelled example images from the shifted data distribution. We illustrate the effectiveness of the proposed method to detect and correct performance drift in mammography-based breast cancer screening and on publicly available histopathology data. We show that the proposed method can preserve the expected performance in terms of sensitivity/specificity under various realistic scenarios of image acquisition shift, thus offering an important safeguard for clinical deployment.
Artificial intelligence (AI) holds the promise for more objective, accurate, and cost-effective analysis of imaging data and could fundamentally transform clinical workflows in image-based diagnostics and population screening. The use of AI could help to ease the pressure on health services, for example, through automated prioritisation of critical cases, or by providing second opinions in diagnostic screening.
Different use cases will have different requirements on AI performance, depending on the role of the AI system within the clinical workflow. An AI system used for triaging or prioritisation would be expected to have near-perfect sensitivity (SEN), while a low specificity (SPC) may be acceptable. AI as a second reader in double reading breast cancer screening, on the other hand, may be expected to perform at similar SEN/SPC levels as a human reader. Many AI systems are versatile prediction models that can be used at different operating points in terms of a specific clinically meaningful SEN/SPC trade-off. Here, an operating point is associated with a calibrated threshold on the continuous AI prediction score. The thresholds are often pre-determined, ideally as part of large-scale validation studies. Thresholds may also be adjusted as part of local optimisation using historical data from a new deployment site. Here, the assumption is that such validation data is, and remains, representative of new data from unseen patients and the associated operating point is within approved values.
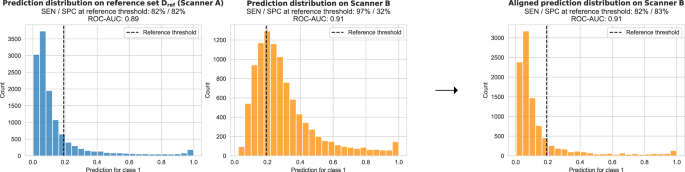
Changes occurring after deployment pose a fundamental challenge to medical imaging AI. Current systems are susceptible to differences in the image characteristics. Changes to the input images, for example, due to replacement of scanner hardware or updates to the image reconstruction and processing software, can cause differences in the AI output predictions (see Fig. 1). These changes may occur any time after deployment and are often outside of the control of the AI manufacturer. While changes in the image characteristics may not necessarily affect the overall predictive power (i.e., the ability to discriminate between positive and negative cases), any shift or drift in the output distribution may invalidate the calibrated thresholds. This would directly impact the SEN/SPC trade-off, and thus, the intended operating point of the AI system. If undetected, such clinical performance drift could result in under- or overdiagnosis and have severe consequences on patient safety.
There is an urgent need for an effective methodology for monitoring AI in real-world deployments, enabling automated correction of performance drift that is caused by image acquisition shifts. The topic of performance monitoring is a pressing matter for the practical deployment of machine learning models, in particular in critical applications such as disease detection. In the past, some methods have been proposed to detect such performance drifts and update models, but these all require human annotations of new samples. However, obtaining annotations in near real-time and linking them with the acquired images is usually not possible in clinical practice, in particular in applications such as breast cancer screening where confirmed diagnosis (e.g., biopsy-proven malignancy) is not available at the time of image analysis. Some methods have been proposed to automatically detect shifts based on statistical tests comparing model predictions, but there remains an unmet need for methods allowing to automatically correct performance drift in the absence of any diagnostic information (such as disease labels). This is precisely the focus of this work.
In this work, we propose and evaluate a simple, generic, and effective approach of unsupervised prediction alignment (UPA) which is capable of detecting and correcting AI clinically relevant performance drift caused by acquisition shift. Our experiments demonstrate the effectiveness of UPA in several real-world scenarios in the context of breast screening and histopathology. In the breast screening application, we first show that UPA is able to adapt outputs of a model optimised on one hardware vendor to recover the desired SEN/SPC performance on different vendors across three large-scale UK breast screening datasets. We confirm the generic nature of UPA using the publicly available WILDS Camelyon17 dataset showing that a classification model optimised on a particular staining protocol can automatically adapt to a new staining protocol. Importantly, UPA is designed such that it allows for continuous recalibration as it automatically detects and adjusts to shifts observed in the prediction distribution over time. We showcase this by simulating multiple acquisition shift scenarios including the introduction of new scanners and updates to the image processing software. We discuss data requirements, assumptions, and limitations of the proposed method. We believe this work is of interest to anyone concerned about the safety and reliability of medical imaging AI including AI developers, healthcare professionals, patients, regulators, and policymakers.
