Vision Language Model (VLM) is an advanced artificial intelligence system that combines natural language understanding with image recognition capabilities. Like OpenAI’s CLIP and Google’s BigGAN, VLMs can comprehend textual descriptions and interpret images, enabling various applications in fields such as computer vision, content generation, and human-computer interaction. They have demonstrated impressive capabilities in understanding and generating text in context with visual content, making them a pivotal technology in the AI landscape.
Researchers from Google Research, Google DeepMind, and Google Cloud contrasts Vision Transformer (ViT) models pre-trained with classification versus contrastive objectives, with contrastive pretrained models, particularly SigLIP-based PaLI, outperforming in multimodal tasks, notably localization and text understanding. The researchers scaled the SigLIP image encoder to 2 billion parameters, achieving a new multilingual cross-modal retrieval state-of-the-art. Their study advocates pre-training visual encoders on web-scale image-text data instead of classification-style data. Their approach reveals the benefits of scaling up classification pretrained image encoders, as demonstrated by PaLI-X in large Vision Language Models.
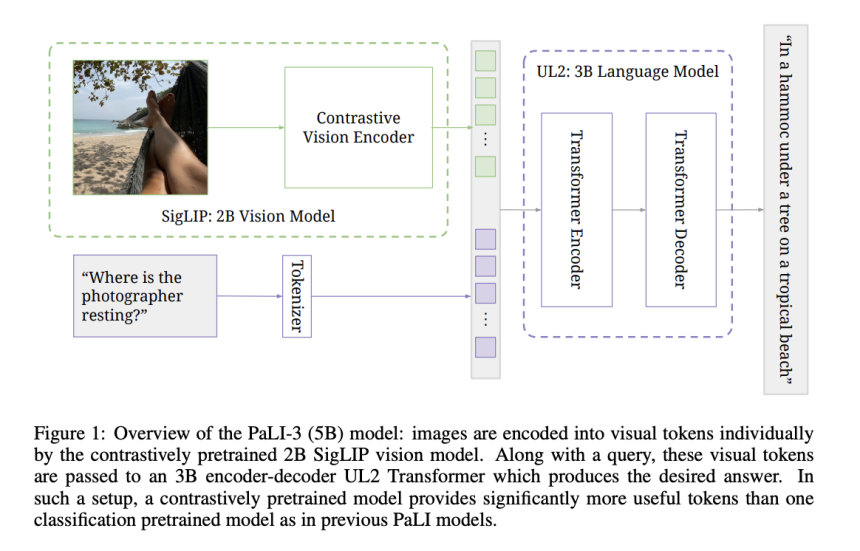
Their study delves into scaling VLM while underscoring the importance of smaller-scale models for practicality and efficient research. It introduces PaLI-3, a 5-billion-parameter VLM with competitive results. PaLI-3’s training process involves contrastive pre-training of the image encoder on web-scale data, improved dataset mixing, and higher-resolution training. A 2-billion-parameter multilingual contrastive vision model is introduced. Ablation studies confirm the superiority of contrastively pretrained models, especially in tasks related to localization and visually-situated text understanding.
Their approach employs a pre-trained ViT model as the image encoder, specifically ViT-G14, using the SigLIP training recipe. ViT-G14 has around 2 billion parameters and serves as the vision backbone for PaLI-3. Contrastive pre-training involves embedding images and texts separately and classifying their correspondence. Visual tokens from ViT’s output are projected and combined with text tokens. These inputs are then processed by a 3 billion parameter UL2 encoder-decoder language model for text generation, typically driven by task-specific prompts like VQA questions.
PaLI-3 excels compared to larger counterparts, particularly in localization and visually situated text understanding. The SigLIP-based PaLI model, with contrastive image encoder pre-training, establishes a new multilingual cross-modal retrieval state-of-the-art. The full PaLI-3 model outperforms the state-of-the-art in referring expression segmentation and maintains low error rates across subgroups in detection tasks. Contrastive pre-training proves more effective for localization tasks. The ViT-G image encoder of PaLI-3 excels in multiple classification and cross-modal retrieval tasks.
In conclusion, their research emphasizes the benefits of contrastive pre-training, exemplified by the SigLIP approach, for enhanced and efficient VLMs. The smaller 5-billion-parameter SigLIP-based PaLI-3 model excels in localization and text understanding, outperforming larger counterparts on diverse multimodal benchmarks. Contrastive pre-training of the image encoder in PaLI-3 also achieves a new multilingual cross-modal retrieval state-of-the-art. Their study underscores the need for comprehensive investigations into various aspects of VLM training beyond image encoder pre-training to enhance model performance further.
